

Wikidata is a free and open knowledge base built collaboratively by volunteers. It contains over 119 million structured data entries, curated by more than 24,000 contributors worldwide.
Part of the Wikimedia ecosystem alongside Wikipedia, it provides linked open data that supports knowledge across multiple projects. The platform has always been machine-readable, but its structured format made it challenging to use with generative AI systems until now, that is.
Wikimedia Deutschland has launched the Wikidata Embedding Project to bridge this divide.
Wikidata Embedding Project: What is It?
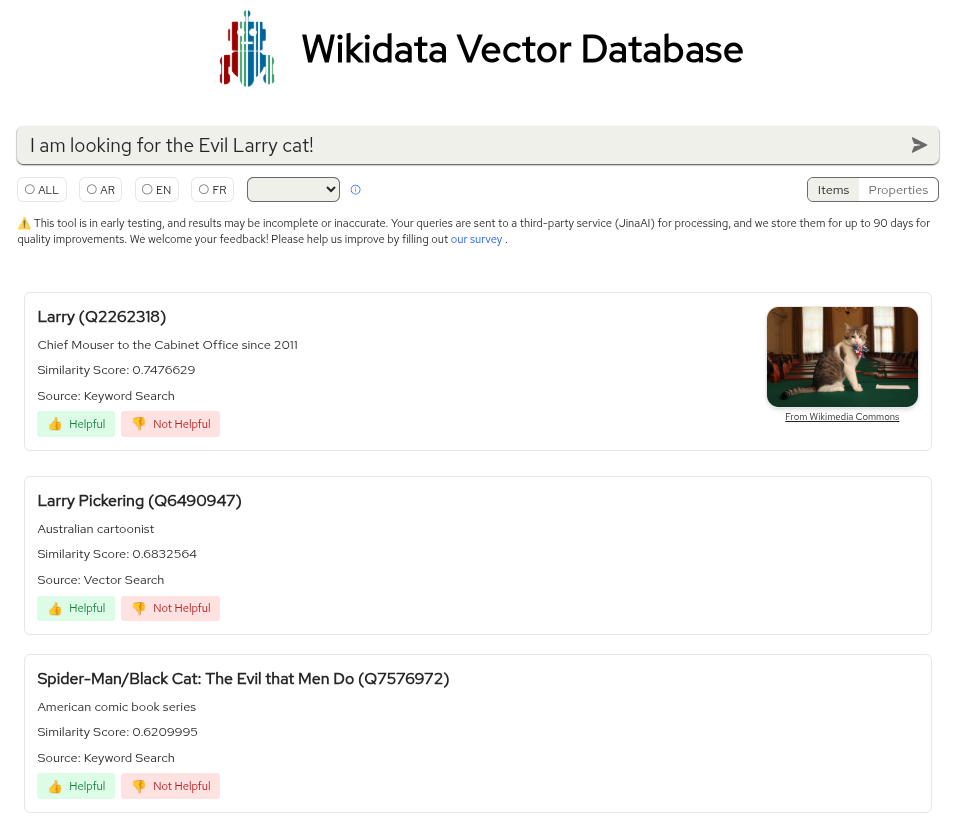
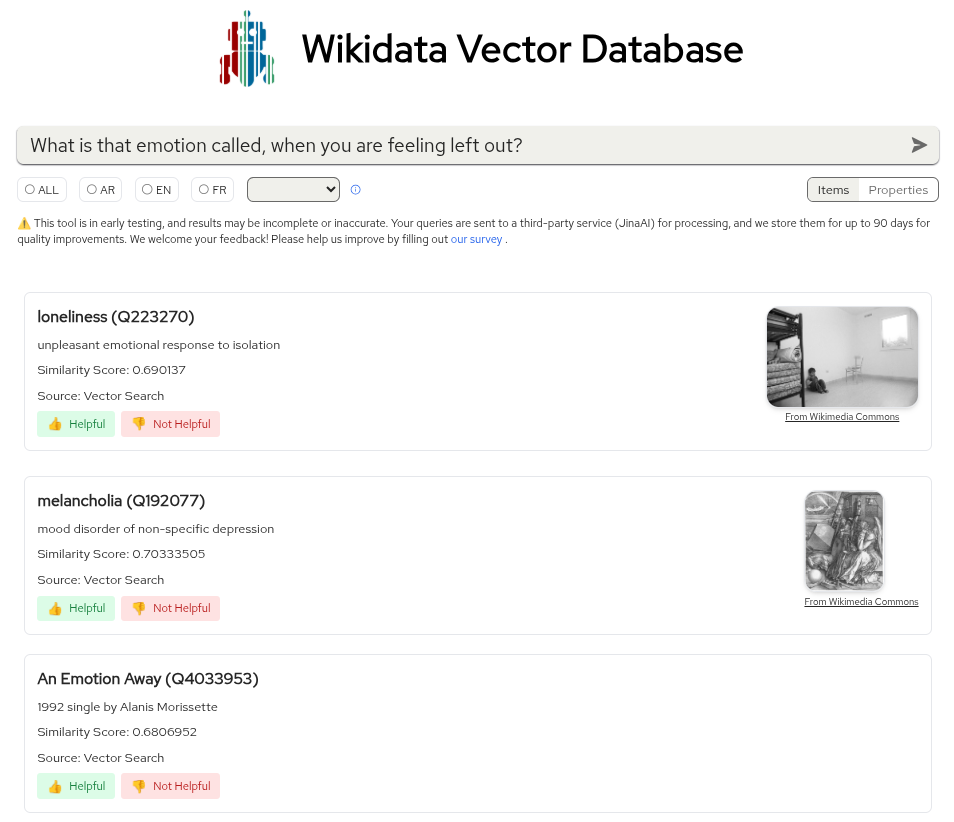
I ran two searches, one for Evil Larry and the other for an emotion.
It is a new vector database that makes Wikidata's knowledge accessible to AI applications. If you didn't know, a vector database stores information as high-dimensional numerical representations, allowing AI systems to find concepts based on meaning rather than just keywords.
This enables semantic search capabilities that understand context and relationships.
The project is completely open source and free to access. Developers can now integrate Wikidata's multilingual, verifiable data directly into large language models. This provides a transparent alternative to proprietary datasets controlled by Big Tech, where the sources and accuracy of training data often remain hidden.
The database is positioned specifically for building generative AI applications with trustworthy foundations.
According to Lydia Pintscher, Wikidata Portfolio Lead, the project "advances trustworthy, transparent AI through an open, public-interest dataset grounded in verified data." It aims to reduce hallucinations and ensure traceability in AI-generated content.
Technical Info and Early Experience
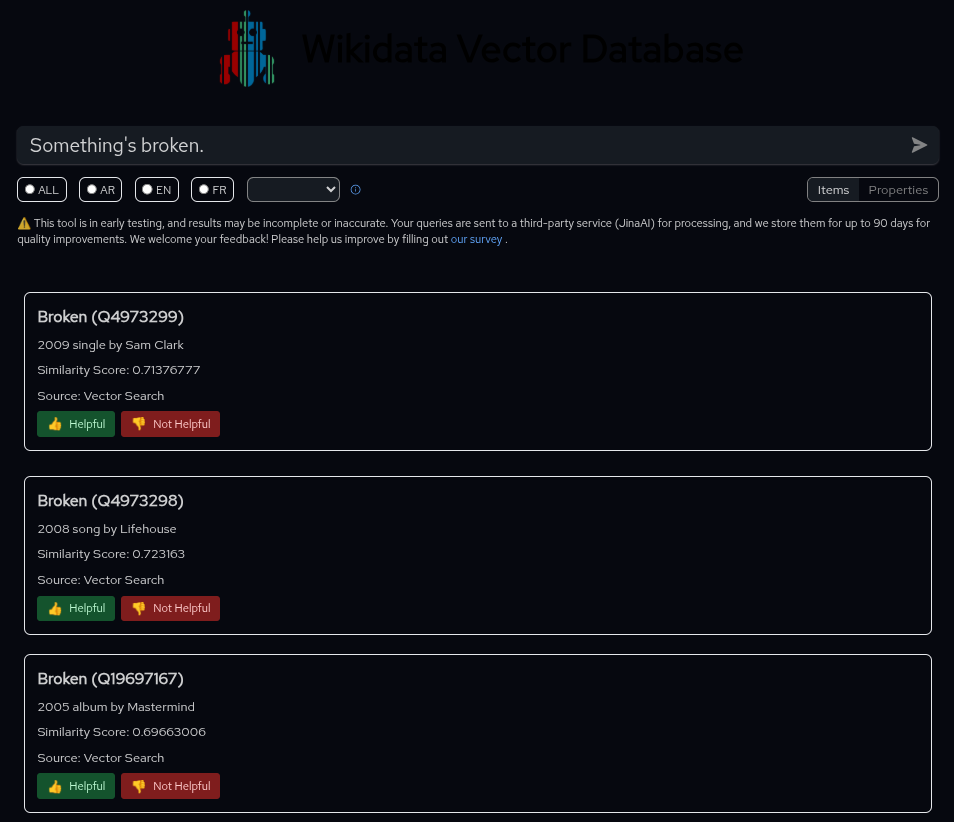
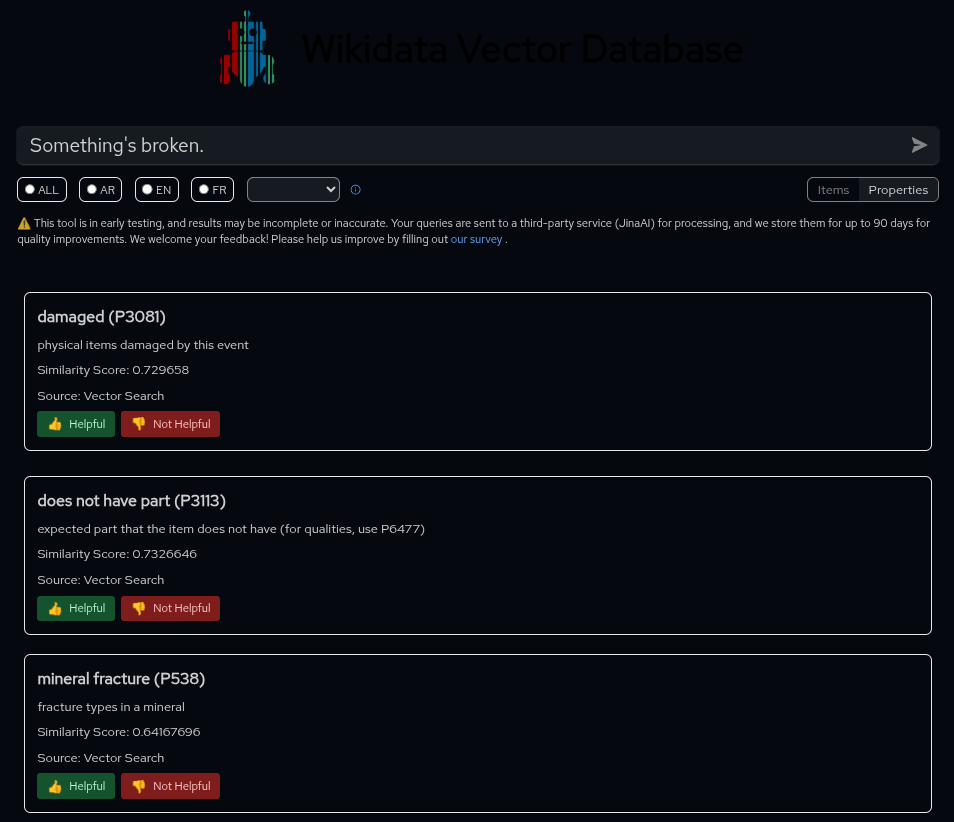
Wikidata Embedding Project items search on left, properties search on right.
Since September 2024, Wikimedia Deutschland has worked jointly with Jina.AI and DataStax to build this infrastructure. The system uses Jina's embedding model, which supports over 100 languages and handles up to 8,192 tokens of input. The vectors are stored in DataStax's Astra DB, a scalable vector database designed for AI applications.
The database currently supports English, French, and Arabic, with more languages planned. It offers both keyword and natural language queries using a hybrid approach that combines keyword matching with semantic vector search.
Beyond basic search, the vector database enables several advanced applications.
These include fact-checking, named entity disambiguation, zero-shot classification, and semantic visualizations of the knowledge graph. It also supports GraphRAG, which combines vector and graph-based reasoning for more sophisticated retrieval patterns.
I took it for a quick test run, searching terms like "I am looking for the Evil Larry cat!" and "What is that emotion called, when you are feeling left out?" The search results took their time to appear, but were mostly relevant. The first query proved challenging, though that is something even Proton's Lumo struggled to handle properly.
Suggested Read 📖
As for the interface, it supports dark mode, but visibility suffers significantly. The project logo essentially disappears when dark mode is enabled, making navigation less intuitive. However, the interface does include useful filters that let you switch languages and toggle search criteria between items and properties.
Of course, these issues are completely acceptable given the project's current status. The database page clearly states it's in an early testing phase. Performance hiccups and interface bugs are expected when you're transforming 119 million knowledge entries into a vector database.
You can take the Wikidata Embedding Project for a test run on the official instance hosted by Wikimedia. No registration or API keys are required to start exploring the database and testing semantic searches across its vast knowledge base.
If you are looking for more, then Wikimedia Deutschland is hosting a free webinar on October 9, 2025, to demonstrate the database and explain how it reduces AI hallucinations. Developers and other interested people can join to learn about integrating the vector database into their applications.
- Even the biggest players in the Linux world don't care about desktop Linux users. We do.
- We don't put informational content behind paywall. Your support keeps it open for everyone. Think of it like 'pay it forward'.
- Don't like ads? With the Plus membership, you get an ad-free reading experience.
- When millions of AI-generated content is being published daily, you read and learn from real human Linux users.
- It costs just $2 a month, less than the cost of your favorite burger.
Become a Plus Member today and join over 300 people in supporting our work.







